-
هفتهای که گذشت (۱)
به نام خدا
کتاب
تنها کتابی که این هفته میخوندم Superintelligence هست. امیدوارم بودم که فردا بتونم تمومش کنم، ولی فکر کنم تموم نمیشه. واقعاً خوندن این کتاب آسون نیست.
پادکست
این هفته به دو قسمت از پادکست Rationally Speaking گوش دادم. قسمت اولی که گوش دادم در مورد آزادی بیان و کنترلش توسط شرکتهای فناوری، بخصوص شبکههای اجتماعی بود. موضوع خیلی مهمیه و فکر میکنم اخیراً این موضوع خیلی زیاد اهمیت پیدا کرده.
RS 200 - Timothy Lee on "How much should tech companies moderate speech?"
دومین قسمتی که گوش دادم و واقعاً فوقالعاده بود در مورد چیزی بود که شاید بشه ترجمه کرد «تحریف اولویت». بیشتر از این کلمهای هم نباید در مورد این قسمت بگم، چون باید به این قسمت از این پادکست گوش کرد. فکر میکنم بعد از شنیدن این قسمت خیلی بهتر بشه در مورد اتفاقات اجتماعی اخیر که تو ایران داره میوفته فکر کرد.
RS 198 - Timur Kuran on “Private Truths and Public Lies"
ویدیو
ویدیوی خیلی خوبی که این هفته دیدم سخنرانی Yuval Noah Harari توی اجلاس داووس امسال بود. Harari با دو کتاب Sapiens و Homo Deus معروف شد که کتابهای خیلی مهمی هستن. توی لیست کتابهایی که امسال باید بخونم این دو تا کتاب هستن. توی این سخنرانی هم فهمیدم که امسال آخرای تابستون قراره سومین کتابش هم منتشر بشه.
-
دومین عصر ماشین
به نام خدا
اخیراً خوندن کتاب «دومین عصر ماشین» [۱] رو تموم کردم. توی این پست اشارهی کوتاهی به مطالب اصلی کتاب میکنم.
خلاصه
این کتاب که نوشتهی دو اقتصاددان هست تمرکز بیشتری روی مسائل و تعاریف اقتصادی داره، ولی بحثهای جالبی در این کتاب در مورد تکنولوژی (های دیجیتال) مطرح شده. قسمت اول کتاب از اینجا شروع میشه که بررسی میکنه در تاریخ بشریت، بزرگترین اتفاقی که بشریت رقم زده انقلاب صنعتی بوده که گفته میشه با اختراع موتور بخار در سال ۱۷۷۵ شروع میشه. نکتهی جالبی که در این مورد هست اینه که بلافاصله بعد از اختراع موتور بخار تغییرات زیادی ایجاد نشد، بلکه وقتی که اختراع واقعاً وارد بازار شد این تغییرها شروع شدن. یک نمونهی جالبی که از این تاخیر در به کارگیری درست اختراعات جدید در کتاب اومده در مورد برق هست. قبل از اینکه از نیروی برق استفاده بشه، کارخانهها یک یا چند موتور بخاطر در مرکز کارخانه داشتن و بقیهی دستگاهها به طور فیزیکی و مستقیم به این موتور بخار متصل بودن و از اون نیرو میگرفتن. پس این نیازمند یک ساختار خاص در طراحی کارخانهها بود، به طوری که کارخانهها به محوریت موتور بخار طراحی و ساخته میشدن. بعد از اینکه موتورهای برقی اختراع شدن کارخانهها فقط موتورهای بخاری خودشون رو با موتورهای برقی جایگزین کردن و ساختار کارخانهها و در نتیجه بازدهی و خروجی اونها تغییر خاصی نکرد. بعد از ساخت کارخانههای جدید و گذر چندین سال زمان، با تغییر ساختار کارخانهها و واحدهای صنعتی تاثیر استفاده از موتور برق خودش رو نشون داد. در ساختار جدید دیگه قسمتهای مختلف کارخانه و دستگاههای تولیدی به محوریت یک یا چند موتور برقی ساخته نمیشدن، بلکه میتونستن پخش باشن و فضای بیشتری رو پوشش بودن و در نتیجه در چیدمان اونها میشد معیارهای دیگهای رو بهینه کرد. همین تغییر ساختاری در کنار وجود اختراع جدید (موتور برقی) باعث شد که این اختراع جدید به بازار معرفی بشه و شروع به ایجاد تغییرات فراوان در زندگی بشر بکنه.
بعد از بحث در مورد مهمترین اتفاق در تاریخ بشریت، بحث به سمت دومین اتفاق مهم و معاصر هدایت میشه که قراره بر همه چیز تاثیر بگذاره. نکتهی جالب اینه که عصر ماشینی جدید، دومین عصر پر اهمیت در تاریخ بشریت هست، نه سومین و یا بیشتر. شاید فکر کنید که قطعاً اتفاقات خیلی مهمی بعد از انقلاب صنعتی افتاده که باعث شدن سرنوشت بشریت تغییر بکنه (مثلاً جنگهای جهانی) ولی از روی بررسی دادههای تاریخی معیارهای مختلفی مشخص میشه که واقعاً اینطوری نشده. این معیارها و نتیجهگیری رو مثلاً میتونید به صورت خلاصه توی این پست بخونید. به نظرم خیلی پست جالبی هست.
وقتی که بحث در کتاب وارد عصر ماشینی دوم میشه مسئلهای به نام رشد نمایی مطرح میشه که مبنای تقریباً همهی پیشبینیها و بحثهای این کتاب در مورد عصر جدید هست. به طور خلاصه نویسندهها عقیده دارن هنوز عصر دوم ماشینی به اندازهی کافی اثرش رو روی زندگی بشریت نذاشته، ولی اثراتی هم که تا به حال گذاشته همه از یک روند نمایی پیروی میکنن، پس چون این روند نمایی قراره در آینده هم وجود داشته باشه بنابراین در آیندهای نزدیک اثر پیشرفتهای جدید خیلی زیاد خواهند بود. حالا اینکه واقعاً این معیارها از یک روند نمایی پیشبینی میکنن جای بحثها و اختلافنظرهای بسیاری هست، چون ممکنه که خیلی از این پدیدهها از یک جایی به بعد به یک فلات صاف بخورن و حالت اشباع پیش بیاد. ولی خب تا زمان نگذره نمیشه در این مورد قضاوت کرد، چون تا الان همهی این معیارها این روند نمایی رو داشتن، ولی حفظ این روند نمایی در آینده به راحتی قابل تصور نیست.
یکی دیگه از نکات جالب کتاب در مورد جمعیت هست. انقلاب صنعتی مصادف میشه با رشد بسیار زیاد جمعیت. بخاطر همین این بحث وجود داره که یک چرخهی سازندهای بین ابداعات و ایدههای جدید و افزایش جمعیت وجود داره. پیشرفت فناوری حاصل از انقلاب صنعتی باعث افزایش جمعیت شد و این افزایش جمعیت باعث شد که افراد زیادی در مورد مسائل فکر کنن و ایدههای بیشتری به وجود بیاد و در نتیجه نوآوری بیشتری هم ایجاد بشه. در این مورد از اقتصاددان Julian Simon نقل میکنند که:
این ذهن انسان هست که از نظر اقتصادی، به اندازه یا حتی بیشتر از دستها و دهان انسان اهمیت داره. در طولانی مدت مهمترین تاثیر اقتصادی اندازه و رشد جمعیت، مشارکت افراد بیشتر در افزایش دانش کاربردی هست؛ و این مشارکت به اندازهای بزرگ هست که در طولانی مدت هزینههای افزایش جمعیت رو پوشش بده [۲].
بحث مهم دیگهی این کتاب در مورد دیجیتالشدن همه چیز هست. اگر خوب به زندگی معاصر نگاه کنیم میبینم که جنبههای زیادی از زندگی دیجیتال شدن. همین دیجیتال شدن مثلاً باعث شده که هزینهی بازنشر و بازتولید تقریباً صفر باشه. وقتی یک قطعهی موسیقی تولید میشه یک مقدار هزینهی اولیه صرف تولید اون میشه، ولی بعد از اون هزینهی نشر و بازتولیدش تقریباً صفره؛ کپی کردن بیتها یک عمل تقریباً رایگانه. همین رایگان بودن بیشتر چرخهی تولید، انتشار، و استفاده از خیلی از کالاها باعث میشه که خیلی از بحثهای اقتصادی در مورد تولید کالا و تقابل عرضه و تقاضا در مورد کالاهای دیجیتال صدق نکنن. یکی از اثرات این میشه بازار «برندهی تمامخواه» [۳]. در این بازار دیجیتال معمولاً فقط یک برندهی اصلی وجود داره و بقیهی بازیگرها بازنده هستن. مثلاً نمونهی نرمافزارها رو در نظر بگیرید. ممکنه که در مورد یک موضوع نرمافزارهای متعددی وجود داشته باشه، ولی از بین این همه گزینه معمولاً فقط یک گزینه هست که بیشتر استفاده میشه و بقیه استفادهی زیادی ندارن. این اتفاق (که یکی از نتایج دیجیتال شدن بازارها است) باعث میشه که اختلاف درآمدی در اقتصاد افزایش پیدا بکنه که یکی از مشکلات بزرگ اقتصادهای معاصر هست.
بعد از این بحثها بحث مهم دیگه اندازهگیری میزان پیشرفت اقتصادی در طول دوران انقلاب صنعتی و عصر معاصر هست. اینکه تکنولوژی مهمترین اثری که داشته این بوده که بهرهوری [۴] رو افزایش داده، یعنی با صرف میزان برابری زمان و هزینه (چه هزینهی مالی و چه هزینهی انسانی) میزان بیشتری تولید امکانپذیر شده. از اون طرف به صورت مفصل در مورد اثر پیشرفت فناوری بر روی مشاغل صحبت شده. در کل تقریباً بر روی اینکه فناوریهای نوین باعث از بین رفتن یک سری شغل میشن اجماع وجود داره. از اون طرف تا الان ایجاد فناوریهای جدید باعث ایجاد مشاغل جدید هم شده. به همین دلیل وقتی در مورد تاثیر فناوریهای نوین عصر دوم ماشینی بر روی مشاغل صحبت میشه این پیشبینی هم هست که دوباره شاهد ایجاد مشاغل جدید باشیم. ولی مشکلی که اینجا هست اینه که اگر تکنولوژی خیلی سریع پیشرفت بکنه، به اندازهای که آموزش نتونه به اون اندازه سریع پیشرف بکنه و مفید باشه، نابرابری به صورت کلی افزایش پیدا میکنه. همین مشکلی هست که در عصر حاضر میبینیم. چون وقتی که آموزش عملکرد خوبی نداشته باشه، تعداد افراد بیکار افزایش پیدا میکنه و چون افراد بیکار باعث ایجاد نیاز اقتصادی زیادی نمیشن بخاطر همین نرخ کلی رشد اقتصادی کاهش پیدا میکنه. این خودش باعث میشه که میزان حقوق کاهش پیدا بکنه، بیکاری افزایش پیدا بکنه، و هزینهکرد بر روی منابع انسانی و ابزارهای کاری کاهش پیدا بکنه. این یک دور باطل هست که باعث افزایش نرخ بیکاری و کاهش رشد اقتصادی میشه. از اون طرف به طور خاص در عصر جدید این اتفاق انگیزهی بیشتری برای هزینهکرد در بهکارگیری ابزارهای هوشمند (روباتهای کارگر) بدون نیاز به استخدام انسانها میشه.
درسته که بعد از انقلاب صنعتی پیشرفت فناوری با افزایش کیفیت زندگی و دسترسی بیشتر مردم به امکانات اولیهی زندگی همراه شده، ولی در عین حال نابرابری طبقاتی در جوامع هم خیلی بیشتر رشد کرده. یعنی اینجا دیگه بحث سر تفاوت یک درصد و ۹۹ درصد نیست، بحث سر این هست که نه تنها فاصلهی درآمد و دارایی یک درصد و ۹۹ درصد مردم بیشتر شده، بلکه تفاوت بین یک درصد اون یک درصد ممتاز با بقیهی یک درصدیها هم افزایش پیدا کرده. این رو از بررسی روند رشد سرانهی تولید ناخالص و سرانهی میانهی درآمد میشه فهمید. تا سال ۱۹۷۵ افزایش سرانهی تولید ناخالص باعث افزایش سرانهی میانهی درآمد شده، ولی از سال ۱۹۷۵ دیگه این روند اتفاق نیوفتاده. با وجود اینکه تا سال ۲۰۱۰ سرانهی تولید ناخالص تقریباً دو برابر شده، سرانهی میانهی درآمد رشد خیلی کمتری داشته و فقط به ۱.۲ برابر مقدارش در سال ۱۹۷۵ رسیده. این نابرابری با وجود ویژگیهای خاص اقتصاد عصر جدید باعث میشه که انتظار افزایش نابرابری رو در آینده داشته باشیم. با توجه به اینکه همه آموزش کافی رو ندارن تا در شغلهای جدید مشغول به کار بشن، و حتی مشخص نیست که شغلهای جدیدی قراره به اندازهی کافی ایجاد بشن یا نه، و اینکه در این اقتصاد «برندهی تمامخواه» توزیع ثروت تولیدی یکنواخت نیست، بنابراین دو راهکار برای کاهش نابرابری مطرح میشن. یکی از این راهکارها خیلی مشعور هستن و در خیلی جاها در موردش صحبت شده. ولی راهکار دوم راهکاری هست که من به هیچ عنوان در موردش اطلاعی نداشتم و برام خیلی جالب بود.
راهحل اول توزیع درآمد همگانی هست، یعنی اینکه به هر فردی از جامعه که به سن قانونی رسید یک مقدار کافی حقوق در نظر گرفته بشه، مستقل از اینکه اون فرد شاغل هست یا نه و خودش چه درآمدی داره (شبیه به سیستم یارانه در ایران). یکی از اولین افرادی که موضوع درآمد همگانی رو در سال ۱۷۹۷ مطرح کرده Thomas Paine بوده که گفته باید به هر کسی مقداری کافی درآمد داده بشه تا جبرانی باشه بر این حقیقت ناعادلانه که بعضی از افراد در خانوادههایی به دنیا اومدن که صاحب زمین هستن، در حالی که بقیه در هنگام به دنیا اومدن از این منعفت بیبهره بودن (همون ژن خوب خودمون). یکی از موضوعاتی که در مورد این راهحل مطرح میشه و به عنوان یکی از نکات منفی این راهحل شمرده میشه این بحث هست که خیلی از انسانها باید شاغل باشن و مشغول بودن به شغل باعث میشه که منزلت و هدف اجتماعی افراد حفظ بشه. مثلاً در کتاب از جامعهشناس William Julius Wilson نقل شده که تبعات بیکاری بالا در یک جامعه خیلی ویرانگرتر از تبعات فقر بالا در یک جامعه هست [۴].
راهحل دوم که برای من کاملاً جدید و البته خیلی جالب بود از اقتصاددان برندهی جایزهی نوبل Milton Friedman هست که «مالیاتِ منفی بر درآمد» [۵] رو مطرح کرده. ایدهی کلی اینه که اگر مثلاً هر فرد شاغل تا سقف از پیش تعیین شدهای معاف از پرداخت مالیات بر درآمد باشه، در این صورت اگر درآمد کسی کمتر از این سقف باشه باید ازش مالیات منفی گرفته بشه؛ یعنی اینکه مقداری پول بهش داده بشه. مثلاً تا جایی که من میدونم افراد شاغل در ایران تا سقف دو میلیون تومان معاف از مالیات بر درآمد هستن و میزان مالیات برای ردیف بعدی ۱۵٪ هست (اصلاً در مورد این اعداد مطمئن نیستم، صرفاً به عنوان یک مثال در نظر بگیرید). پس با این حساب اگر کسی حقوق برابر با یک میلیون تومان داشته باشه، مالیات منفی بر مابهالتفاوت درآمدش حساب میشه و این مالیات به فرد داده میشه؛ یعنی در این حالت ۱۵٪ اون یک میلیون تومان میشه ۱۵۰ هزار تومان که به فرد داده میشه. این راهحل نه تنها باعث میشه که برابری اقتصادی بیشتر بشه، بلکه همچنین باعث میشه که افراد تشویق به اشتغال بشن، حتی اگر درآمدشون کم باشه.
نظر
بخاطر اقتصاددان بودن نویسندههای کتاب، بحث اصلی کتاب اقتصاد هست. با توجه به اینکه من در زمینهی اقتصاد مطالعه نداشتم، فکر میکنم نتونستم به اندازهی خوبی به نکات و بحثهای اقتصادی کتاب پی ببرم. ولی تعدادی از ایدهها و بحثهای اقتصادی برای من خیلی جدید و جالب بودن و این من رو متقاعد کرده که بیشتر در مورشون اطلاعات کسب کنم. تاکید زیاد این کتاب بر اهمیت آموزش هم نکتهی جالب دیگهای از کتاب هست.
با وجود بحثهای مهم و تخصصی، فکر میکنم که کتاب برای عموم خوانندهها نوشته شده و نیازی نیست که مخاطب دانش ویژهای در این زمینه داشته باشه که بتونه از این کتاب چیزهای جدیدی یاد بگیره و دانستههای جدیدش رو به کار ببنده. ولی همین باعث شده که در خیلی از قسمتهای کتاب حس بکنم که کتاب خیلی گذرا به موضوعی اشاره کرده و وارد عمق اون مطلب نشده. بخاطر همین خیلی دوست دارم که در مورد ایدهها و موضوعات مطرح شده توی این کتاب مطالعهی بیشتری داشته باشه، بخصوص موضوع مالیات منفی بر درآمد.
فکر میکنم در این حین که داریم خودمون رو برای آینده آموزش میدیم و آماده میکنیم، باید منتظر باشیم و ببینیم که چقدر فرضیات این کتاب در مورد نرخ نمایی رشد خیلی چیزها درست و بهجا بوده.
خلاصه اگر دنبال کتابی هستید که بحث در مورد آیندهی تکنولوژی و تاثیر اون رو وارد حوزهی تخیل نکرده و نزدیک به واقعیت مونده این کتاب رو خیلی پیشنهاد میکنم.
منابع
[1] Brynjolfsson, Erik, and Andrew McAfee. "The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies." WW Norton & Company, 2014. (link)
[2] همان، صفحهی ۹۴.
"It is your mind that matters economically, as much or more than your mouth or hands. In the long run, the most important economic effect of population size and growth is the contribution of additional people to our stock of useful knowledge. And this contribution is large enough in the long run to overcome all the costs of population growth."
[3] Winner-take-all
میدونم ترجمهی خوبی نیست ولی ترجمهی بهتری به ذهنم نرسید. اگر ترجمهی بهتری میدونید توی قسمت نظرات بنویسید.
[4] همان، صفحهی ۲۳۵.
[5] The Negative Income Tax
-
هوش مصنوعی برای جامعه
به نام خدا
فکر کنم دور از ذهن نیست اگر بقیهی مطالب این وبلاگ رو خونده باشید بدونید که مهمترین زمینهای که روش تمرکز دارم در حال حاضر هوش مصنوعی هست. از زمانی که تورینگ مقالهی «ادوات محاسبهگری و هوش»[۱] رو منتشر کرد ۶۸ سال میگذره. تو این مدت زمان خیلی اتفاقها افتاده و هوش مصنوعی خیلی سرد و گرم کشیده. ولی حالا زمانی هست که بیشتر از هر وقت دیگهای آدمهای کارپشته و تازهکارهایی مثل من وارد این حوزه شدن. شاید بشه گفت الان مهمترین تکنولوژی حاضر بشر هست که داره به شکوفایی میرسه. احتمالاً برای همه هم واضح باشه که تو چهار پنج سال اخیر پیشرفتش قابل مقایسه با قبل نبوده. حالا کاملاً از دانشگاهها خارج شده و توی جامعه دنبال میشه و به طور مستقیم به اکثر جوامع تاثیر میگذاره.
احتمالاً اگر دسترسی به اینترنت داشته باشید، در مورد این هم اطلاع دارید که کلی آدم دارن در مورد این صحبت میکنن که اگر بتونیم به هوش عمومی مصنوعی [۲] برسیم، به احتمال زیادی نسل بشر منقرض خواهد شد. در مقابل یه سری هم هستن که میگن اگر به هوش عمومی مصنوعی برسیم دیگه زندگی انسانها تبدیل به بهشت خواهد شد. به هر دو دستهای که زمان حال یا آیندهی نزدیک رو ول کردن و دارن در مورد آیندهی نامعلوم دستیابی به هوش عمومی مصنوعی صحبت میکنن، میگن تکینهگراها [۳]، کسایی که غالباً خیلی احساسی و تعصبی در مورد این مسائل صحبت میکنن. البته حرفهاشون خیلی بیهوده هم نیست، واقعاً این خطر به شکل جدی وجود داره. ولی معمولاً وسط این حرفهای اغراقآمیز در مورد یک آیندهی نامعلوم و شاید نه چندان نزدیک، اهمیت زمان حال و آیندهی خیلی نزدیک خیلی گم میشه. اون قدری که به حرفهای تکینهگراها گوش داده میشه و کار انجام میشه، کار در مورد اثرات هوش مصنوعی بر روی جوامع و انسانها انجام نمیشه.
شاید آخرین تکنولوژی خیلی مخربی که بشر بهش دست یافته باشه تکنولوژی تولید سلاحهای هستهای باشه. معمولاً وقتی در مورد خطرات هوش عمومی مصنوعی صحبت میشه، حتماً حرف سلاحهای هستهای هم وسط میاد. ولی فکر میکنم تفاوت عمدهای بین این دو تکنولوژی وجود داره که زیاد بهش توجه نمیشه. اگر یک دولت، مثل دولت امریکا، با یه پروژهی خیلی بزرگ مقیاس مثل پروژهی منهتن تونست به این تکنولوژی دست پیدا بکنه و بعد از سالها این تکنولوژی فقط دست «دولت»های معدودی هست، نشون میده که موانع ورود به این حوزه خیلی خیلی بزرگ هستن. ولی، موانع ورود به حوزهای مثل هوش مصنوعی اصلاً اونقدر بزرگ نیستن. درسته برای یه چند تا دانشجو خریدن کارت گرافیکی سخت باشه، ولی همزمانی وجود اینترنت، وجود داده، وجود زیرساختهای محاسباتی، و حرکت ارزشمند open source و مشابه اون در به اشتراک گذاری تحقیقات، یک همزمانی منحصربفرد هست. فکر کنید به جای اینکه پروژهی منهتن یک پروژهی مخفی باشه، با چند نفر محدود که روش کار میکردن، این یه حرکت بینالمللی باشه بین تعداد زیادی آدم و شرکت، که کلی امکانات در اختیار دارن و آزادانه همهی نتایج و دستاوردها رو به اشتراک میذارن. مثلاً فرض کنید اپنهایمر به یه چیز جدید در مورد تکنولوژی هستهای میرسه، بعد میشینه آخر هفته یه مقاله مینویسه، جمعه شب (یا به طور مشابه یکشنبه شب) مقاله رو به آرکایو [۴] سابمیت میکنه و دو روز بعد، صبح دانشمندان روسی یا آلمانی که از خواب بیدار میشن میرن مقالهی اپنهایمر و دوستان رو دانلود میکنن و از آخرین دستاوردهاشون در مورد ساخت سلاحهای هستهای استفاده میکنن. تصور میکنید این شرایط رو؟ این شرایط برای هوش مصنوعی وجود داره. ولی اتفاقات کوتاه مدتی که توی هوش مصنوعی میوفته به اندازهی یک سلاح هستهای صدا نمیکنن. خیلی کوچکتر هستن. یک سلاح هستهای تاثیر مخربی رو جمعیت نسبتاً کمی (نسبت به جمعیت کل جهان) میذاره. ولی یک محصولی که هوش مصنوعی داشته باشه میتونه تاثیر خیلی کمی روی جمعیت خیلی بزرگی بذاره. تاثیرش هم معمولاً روی هر فرد به اندازهای کمه که هیچ کسی رو از اتفاقی که داره میوفته خبردار نمیکنه. مشکل اصلی هوش مصنوعی دقیقاً چیزی هست که باعث شده به این وضعیت پیشرفتهی فعلیش برسه، راحتی پیشبردش.
اول این ویدیو رو ببینید:
شاید اول فکرتون به این سمت بره که اگر دولتها به این تکنولوژیها دسترسی داشته باشن (که قطعاً دارن) چه کارهایی میشه باهاش کرد که اهداف بیشترشون در تضاد حقوق شهروندی میتونه باشه. ولی مسئلهی اصلی اینه که دسترسی به تکنولوژی اونقدر راحت هست که نه تنها دولتها، بلکه هر کس دیگهای میتونه بهش دسترسی داشته باشه و بر اساس نیازهاش تغییرش بده.
حال این ویدیو رو ببینید:
این ویدیو ساختگی هست، برای کمپین ایجاد قوانین محدودکننده برای سلاحهای خودمختار [۵]. این ویدیو خیلی باعث ترس و نگرانی من شد. چیزی که توی این ویدیو نشون میدن تکنولوژی عجیب یا دور از دسترسی نیست. شاید یک تیم چند نفرهای که برنامهنویسی بلد هستن بتونن در مدت چند ماه حرکت هوشمندانهی این پهپاد رو درست بکنن. درست کردن بقیهی قسمتهاش هم خیلی زمان نمیبره.درسته تخمینهای من اشتباه هستن، ولی رسیدن به این تکنولوژی نیازی به زمان و هزینه و تخصص (در عمل به اندازهی) بینهایت نداره. با منابع محدودتری هم میشه به این تکنولوژی دست یافت و این خیلی ترسناکه.) شاید کشورهایی که در اونها جایگاه و منزلت قانون بیشتره، مثل امریکا یا کشورهای اتحادیهی اروپا واقعاً بتونن به قوانین محدود کننده دست پیدا بکنن، ولی نگرانی بزرگتر اینجا شروع میشه. کشورهایی که به اندازهی کافی در چارچوب قوانین نیستن و یا تمامیتخواه و سرکوبگر هستن، به راحتی میتونن از این تکنولوژیهای برای مقاصد نادرست استفاده بکنن. علاوه بر اون کشورهای تابع قوانین هم خیلی راحت میتونن این تکنولوژیهاشون رو بر روی ملل دولتهای ضعیفتر امتحان بکنن. بخاطر همینه که پیشرفت تکنولوژی از خیلی جهات خیلی بیشتر باعث ضرر مردمان کشورهای ضعیف از نظر سیاسی و دسترسی به تکنولوژی میشه. این مردمان (ما مردمان) هم از طرف دولتهای خودشون (خودمون) با ابزار تکنولوژی هوش مصنوعی میتونن (میتونیم) مورد سرکوب قرار بگیرن (بگیریم) و هم از طرف دولتهای صادرکنندهی دموکراسی. واقعاً در این زمان خیلی سخته شهروند کشوری بود که در اون کشور به اندازهی کافی و لازم به قوانین احترام گذاشته نمیشه.
ولی خب به هر حال نمیشه جلوی پیشرفت تکنولوژی رو گرفت. اتفاقاً جلوی پیشرفتش رو هم گرفتن اشتباهه. در مورد برخورد با هوش مصنوعی چند تا راهکار اصلی وجود داره. بعضیها عقیده دارن که همهی نتایج و دستاوردها باید آزادانه و به سرعت با همه به اشتراک گذاشته بشه تا برتری استراتژیک زیادی بین طرفهای مختلف وجود نداشته باشه. شاید بشه گفت تا حدودی وضعیت فعلی اهالی دانشگاه و محققان دانشگاهی که در صنعت هستن اینطوری باشه. نظر گروه دیگهای اینه که دستاوردها باید با تامل بیشتری به اشتراک گذاشته بشن. تا وقتی که در مورد درستی و بیخطری دستاوردی مطمئن نشدیم نباید اون دستاورد رو با بقیه به اشتراک بذاریم. دستهی آخر هم نظرشون اینه که کلاً باید همه چیز پشت درهای بسته باشه تا همیشه برتری استراتژیک دست ما (که برگزیدهترین افراد برای داشتن این اسرار هستیم و صلاح همهی بشر رو بیشتر میدونیم) باشه و دست «انسانهای بد» نیوفته. البته بدیهیه که این رویکرد خیلی شکننده است.
من به اندازهی کافی در مورد این رویکردها فکر نکردم، ولی نظر فعلیم اینه که اشتراکگذاری بدون وقفه و آزادانه شاید بهترین روش فعلی باشه. ولی قطعاً این روش پایداری نیست و بهترین گزینه نیست. این روش تضمین نمیکنه که همهی طرفین آزادانه دارن همهی نتایج و دستاوردهاشون رو به اشتراک میذارن و اتفاقاً کسایی که با قوانین این بازی، بازی نمیکنن شاید بشه گفت که سود بیشتری میبرن.
از اون طرف به کارگیری روزمرهی تکنولوژیهای مبتنی بر هوش مصنوعی در همهی زمینههای زندگی حتماً اثرات منفی مختلفی داره ولی نمیشه جلوی این رو گرفت. به نظر شما چطوری میشه اثرگذاری این تکنولوژی رو مثبتتر کرد؟ واقعاً آیا راهحلی وجود داره؟
اگر خیلی مثل گذشته تنبلی بر من غلبه نکنه، در آینده بیشتر در مورد ایمنی هوش مصنوعی [۶] خواهم نوشت.
[1] Turing, Alan M. "Computing machinery and intelligence." Mind 59.236 (1950): 433-460.
[2] Artificial General Intelligence
[3] Singularitarians
[4] arxiv.org/
[5] Autonomous Weapons
[6] AI Safety
-
شنبههای آرکایو (دوشنبه ۱۶ مرداد - شنبه ۲۱ مرداد)
به نام خدا
در مورد شنبههای آرکایو قبلاً نوشتم. این بار تصمیم گرفتم که برای هر هفته پستی بنویسم و مقالات جالبی رو که پیدا کردم معرفی کنم. فعلاً این هفته به صورت آزمایشی این کار رو انجام میدم تا بعد تصمیم بگیرم که آیا ادامه خواهم داد یا نه.
این هفته ۴۷۲ عنوان جدید تو قسمتهای منتخب آرکایو بارگزاری شده که البته این، عدد، تعداد مقالات یکتا نیست. تعداد مقالات یکتا شاید نصف این عدد باشه. دلیلش اینه که بعضی از مقالات ممکنه که در بیش از یک موضوع دستهبندی شده باشن. این بار cs.CV (طبق معمول) بیشترین مقالهی جدید رو با ۱۴۲ عنوان جدید داشت.
قسمتهایی که من دنبال میکنم این قسمتها هستن:
- cs.{AI, CG, CL, CV, IR, LG, NE, RO}
- stat.ML
مقالات منتخب هفتهی گذشته
"Regularizing and Optimizing LSTM Language Models" - 1708.02182
Stephen Merity, Nitish Shirish Keskar, Richard Socher
Salesforce Research
در این مقاله مسئلهی آموزش مدلهای زبانی سطح کلمه (word-level) مورد توجه قرار گرفته و روشهای مختلف بهینهسازی و تنظیم (regularization) مدلهای مبتنی بر LSTM بررسی شدن.
از طریق این روشهای بهبود یافتهی آموزش مدلهای زبانی مبتنی بر LSTM، در این مقاله تونستن به بهترین نتیجه روی دو دیتاست Penn Tree Bank و WikiText-2 دست پیدا کنن.
یکی از این روشها، استفاده از DropConnect با ماسک ثابت در راستای زمان، برای اتصالات پنهان-به-پنهان در فرمولبندی LSTM هست. تفاوت DropConnect با Dropout در این هست که در Dropout ماسک تصادفی بر روی خروجی یک لایه اعمال میشه تا لایهی بعد به عنوان ورودی، نسخهای مخدوششده از خروجی لایهی قبل رو بگیره. در مقابل در DropConnect این ماسک تصادفی بر روی وزنهای یک لایهی fully-connected اعمال میشه.
برای بقیهی اتصالات در این کار از Dropout معمولی استفاده شده، ولی ماسک تصادفی یک بار نمونهگیری شده و در طول دنباله از این ماسک استفاده شده، یعنی در واقع Variational Dropout. کار دیگهای هم که در این مقاله انجام شده استفاده از Dropout بر روی ماتریس Embedding هست، به این شکل که در هر بار نمونهگیری از ماسک تصادفی ممکنه تعدادی از کلمات حذف بشن. طبق معمول یه سری کارهای قبلی در زمینهی یادگیری مدل زبانی و ترجمهی ماشینی، در این کار وزنهای ماتریس Embedding و لایهی خروجی (یا لایهی softmax) مشترک هستن. این کار هم باعث میشه که تعداد پارامترهای مدل کم بشه و هم اینکه یک شهود نظری پشت این کار هست 1.
یک regularization جالب دیگهای که انجام دادن Activation Regularization و Temporal Activation Regularization هست که تقریباً جدید هستن و تو کارهای زیادی قبلاً ندیدم. توی Activation Regularization هدف اینه که خروجی میانی LSTM مقادیر کوچکی بگیرن، یعنی
$$ \alpha L _ 2 (m \odot h _ t) $$. در مقابل در Temporal Activation Regularization هدف اینه که خروجیهای میانی LSTM در طول زمان خیلی متغیر نباشن، یعنی
$$ \beta L _ 2 (h _ t - h _ {t+1}) $$
در کل به نظر میاد که مقالهی خوبی باشه و بشه به نتایجشون اعتماد کرد، هر چند تا جایی که میدونم کد مقاله رو منتشر نکردن. اگر میخوایید از LSTM برای پردازش دنباله استفاده کنید، بخصوص برای مدلهای زمانی، خوندن این مقاله فکر میکنم مفید میتونه باشه.
"Recent Trends in Deep Learning Based Natural Language Processing" - 1708.02709
Tom Young, Devamanyu Hazarika, Soujanya Poria, Erik Cambria
School of Information and Electronics, Beijing Institute of Technology, China; School of Computing, National University of Singapore, Singapore; Temasek Laboratories, Nanyang Technological University, Singapore; School of Computer Science and Engineering, Nanyang Technological University, Singapore
این مقاله به طور کلی به بررسی پیشینه، وضعیت فعلی، و روند پیشرفت روشهای مبتنی بر شبکههای عصبی برای پردازش زبانهای طبیعی پرداخته. اگر تازه میخوایید وارد این موضوع بشید یا حتی اگر میخوایید با تاریخچه و روال فعلی این موضوعات آشنا بشید این مقاله منبع خوبیه برای مطالعهی اولیه.
"Revisiting Unreasonable Effectiveness of Data in Deep Learning Era" - 1707.02968
Chen Sun, Abhinav Shrivastava, Saurabh Singh, Abhinav Gupta
Google Research, Carnegie Mellon University
تا مدتی قبل بزرگترین مجموعه دادگان در دسترس عموم برای کلاسهبندی تصاویر مجموعه دادگان ImageNet بود. ولی شرکتهای بزرگ هر کدوم مجموعه دادگان خیلی بزرگتری داشتن. یکی از این مجموعه دادگان که مال گوگل هست JFT نام داره و حاوی بیش از ۳۰۰ میلیون(!) تصویر با ۱۸۲۹۱ دسته هست. البته برچسبزنی این همه تصویر به صورت خودکار انجام شده و بنابراین دارای خطا هستن. ولی با این حال اندازهی این مجموعه دادگان واقعاً بزرگه. توی این مقاله گوگلیها بررسی کردن که آیا معماریهای معمول دستهبندی تصاویر وقتی که تعداد تصاویر به مقدار قابل توجهی زیاد بشه باز هم میتونن به نتیجهی بهتری دست پیدا بکنن و نمایش بهتری از دادهها رو یاد بگیرن؟ برای این کار یک مدل ResNet-101 رو روی این مجموعه دادگان آموزش میدن (در مورد جزئیات این آموزش توی مقاله نوشته شده) و بعد از این مدل آموزش دیده شده به عنوان مدل اولیه برای چهار downstream task دیگه استفاده میکنن، یعنی کلاسهبندی تصاویر، تشخیص اشیا، قطعهبندی معنایی تصاویر، و تشخیص وضعیت (اسکلت) انسان. اونطوری که حدس زدن نتیجهی این کار دور از انتظار نیست، مدل آموزش داده شده بر روی مجموعه تصاویر JFT-300M و بعد fine-tune شده روی هر مجموعه دادگان تونسته بهترین نتیجه رو توی هر کدوم از این چالشها به دست بیاره.
چون کسی به غیر از گوگل به مجموعه دادگان به این بزرگی دسترسی نداره، تنها میشه امیدوار شد که گوگل مدل آموزشدادهشده بر روی این مجموعه دادگان بزرگ رو منتشر بکنه (تا الان که این کار رو نکرده، بعید میدونم بعد از این هم بکنه).
"Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge" - 1708.02711
Damien Teney, Peter Anderson, Xiaodong He, Anton van den Hengel
Australian Centre for Visual Technologies, The University of Adelaide, Australia; Australian National University, Canberra, Australia; Deep Learning Technology Center, Microsoft Research, Redmond, WA, USA
این مقاله شرح روشی هست که در آخرین مسابقهی پاسخ پرسشهای تصویری VQA 2017 که بر روی نسخهی دوم مجموعه دادگان VQA هم بود تونست مقام اول رو کسب بکنه. تقریباً میشه با نگاهی به تصویر دوم در مقاله کلیت روش رو فهمید. نکات جالب این مدل به نظرم در مقایسه با مدلهای دیگه برای VQA یکی روش استخراج ویژگیهای تصویر هست که از R-CNN استفاده شده، و نکتهی بعدی هم استفاده از ضرب درایه به درایه برای ترکیب ویژگیهای سوال و تصویر هست. این کار تقریباً بر خلاف اکثر کارهای اخیر هست که توی اونها تعاملهای مرتبه بالاتری بین توصیف تصویر و سوال مدلسازی میشن، مثلاً انواع تعامل bilinear به جای ضرب هادامارد ساده. ولی خب در اینجا تونستن البته کار جدیدی که توی این مدل انجام دادن و به خاطر ندارم مدلهای دیگهای این کار رو کرده باشن اینه که مسئلهی VQA رو (با در نظر گرفتن برچسبهای این دیتاست) تبدیل کردن به یه مسئلهی دستهبندی چند برچسبی (Multi-label classification). یه نکتهی خیلی عجیب در مورد این مقاله این هست که این شبکه با استفاده از MATLAB پیادهسازی و آموزش داده شده.
چیزی که باعث شد من خیلی از این مقاله خوشم بیاد، علاوه بر اینکه قسمتهای مختلف کارشون رو خوب توضیح دادن، اینه که Ablation study خیلی مفصلی انجام دادن که دقیقاً تشریح میکنه هر قسمت از مدلشون و هر کاری که انجام دادن چقدر در رسیدن به نتیجهی نهایی تاثیر داشته. همین کار باعث میشه که اعتماد آدم به این کار و نتایجش تقریباً تضمین بشه. ولی اینکه کد این مقاله منتشر نشده و البته اگر هم منتشر بشه با MATLAB نوشته شده یکی از نکات منفی این کار هست، البته در مقابل نکات قوت این کار میشه کاملاً ازشون چشمپوشی کرد.
فکر میکنم از این به بعد اگر کسی بخواد روی مسئلهی VQA کار بکنه باید از این کار شروع بکنه.
"MemexQA: Visual Memex Question Answering" - 1708.01336
Lu Jiang, Junwei Liang, Liangliang Cao, Yannis Kalantidis, Sachin Farfade, Alexander Hauptmann
Carnegie Mellon University, Customer Service AI, Yahoo Research
این مقاله کار بسیار جالبی هست که توجه من رو خیلی جلب کرد و فکر میکنم چیزی هست که در آیندهی نزدیک خیلی دوست دارم روش کار بکنم. این مقاله مسئلهی MemexQA رو معرفی میکنه. این مسئله اینطوری تعریف میشه که اگر یک مجموعه از تصاویر و ویدیوها متعلق به یک فردی داده بشن، هدف اینه که به صورت خودکار به سوالات کاربر جواب بدیم تا کاربر بتونه خاطراتش رو در مورد رویدادهایی که اتفاق افتادن و توی اون مجموعه به تصویر کشیده شدن به خاطر بیاره. مثلاً یه سری تصویر از یک جشن تولد دارید ولی به خاطر نمیارید که جشن تولد کی بوده. هدف این کار اینه که این سیستم بتونه به این سوال که جشن تولد کی بوده پاسخ بده و برای پاسخش هم تعدادی تصاویر از اون مجموعه تصاویر به عنوان مدرک بیاره. برای اینکار یک مجموعه دادگان جدید هم به همین اسم منتشر شده، البته در حال حاضر در دسترس نیست، ولی به زودی خواهد بود. این مسئله و کلیت مقاله به نظرم خیلی جالب هستن و البته مدل اولیهای که ارائه دادن خیلی مدل پیچیدهای نیست. بنابراین فکر میکنم میشه با مدل بهتری نتایج بهتری روی این مجموعه دادگان گرفت. در کل اگر به مسئلهی مطرح شده تو این مقاله علاقه دارید حتماً مقاله رو کامل بخونید.
"TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks" - 1708.02637
Heng-Tze Cheng, Zakaria Haque, Lichan Hong, Mustafa Ispir, Clemens Mewald, Illia Polosukhin, Georgios Roumpos, D Sculley, Jamie Smith, David Soergel, Yuan Tang, Philipp Tucker, Martin Wicke, Cassandra Xia, Jianwei Xie
Google; UptakeTechnologies
این یک مقالهی خیلی جالبی هست که توی کنفرانس KDD 2017 پذیرفته شده و رابط برنامهنویسی
Estimatorرو در کتابخانهی TensorFlow معرفی میکنه. ساختاردهی و مدیریت کد یکی از کارهای سختیه که نیاز به تجربهی زیادی داره. ولی با این حال بعضی وقتها کتابخانهها میتونن با فراهم کردن رابطهای برنامهنویسی خوب ساختاردهی مناسبی به کد کاربر اعمال بکنن. یکی از این ساختاردهیها توی کتابخانهی TensorFlow با استفاده از کلاسEstimatorاعمال میشه که در این مقاله به طور مفصلی در این مورد صحبت کرده. از روی تجربهام فکر میکنم دنبال کردن یک ساختار برنامهنویسی که سطح بالا است و در عین حال انعطافپذیری کافی هم داره هم باعث میشه که پروژه سریعتر جلو بره و هم با گذشت زمان همچنان کد قابل مدیریت باقی میمونه. حدود شش ماه پیش که تصمیم گرفتم آخرین پروژهام رو با استفاده از کتابخانهی TensorFlow شروع کردم خوشبختانه با نمونه کدی شروع کردم که از این رابطهای برنامهنویسی مثل کلاسEstimatorاستفاده میکرد. هر چند استفاده از این رابطها هنوز معمول نیست بین برنامهنویسها، ولی از این انتخاب بسیار راضی هستم. چون باعث شده که با وجود نیاز به تغییرات بنیادین و البته بزرگشدن زیاد کد در طول پروژه، نیازی نباشه که کل کد رو چند بار از اول ساختاردهی بکنم و دوباره بنویسم و یا اینکه مشکلات بزرگی در کد پیش بیاد.اگر میخوایید پروژهای با اندازهی متوسط به بالا با کتابخانهی TensorFlow پیادهسازی بکنید پیشنهاد میکنم از رابطهای برنامهنویسی کلاسهای
EstimatorوExperimentاستفاده کنید و این مقاله رو هم بخونید.پستهای وبلاگ منتخب از هفتهی گذشته
این یه مطلب تقریباً مفصل هست در مورد یک سناریوی غیرمحتمل که البته بیشتر جنبهی فکری داره، تا اینکه واقعاً امکانش وجود داشته باشه. به نوعی یک آزمایش ذهنی.
فرض کنید یک ابرهوش به وجود بیاد که توانایی ذهنی بسیار زیادی داره، خیلی بیشتر از توانایی ذهنی انسانها. بنابراین میشه نتیجه گرفت که این موجودیت توانایی بیشتری هم در زمینهی استدلال در مورد اخلاق و آداب هم داره. حالا فرض کنید که این موجودیت به انسانها و زندگی کردنشون رو ببینه و بعد به این نتیجه برسه که اگر انسانها به دنیا نیان، بنابراین نمیتونن رنجی رو هم متحمل بشن. بنابراین خیلی خیرخواهانه تصمیم میگیره که سیاست تولدستیزی (Anti-Natalism) سیاست خیلی خوبی در مورد انسانهاست.
-
arXiv Saturdays and the ever-growing list of unread papers
به نام خدا
For the past two years, or a little more, I have been following the latest research published on arXiv. I also check the proceedings of relevant conferences, but arXiv is my most important resources for following what is going on in the world of AI.
I am subscribed to the RSS feeds of some of the relevant arXiv sections (cs.CV, cs.LG, cs.NE, cs.CL, etc.). So all new entries are available in my feed reader of choice (Feedly). At first I didn't have a schedule to check the new entries, and sometimes entries got removed after 30 days. However, for the past few months, I follow a plan that helps me keep track of all the latest research. I have arXiv Saturdays, when I check all of the papers added to arXiv during the past week. Why Saturday? Because that's the only day no new entries are added to arXiv. This also helps with amortizing the time needed to check all these papers, since each week a large number of new papers are added to arXiv, for example today that I checked Feedly, there were 470 new entries!
As I scroll through the new entries, the first filter is the title of the paper. Judging by the title I can filter out most of the papers. If I find the title relevant to my own and some of my friends (more on the friends later) research, I move to read the paper's abstract. I not only check out the papers relevant to my own research interests, but I also check some that are relevant to the research interests of a number of my friends. If I find them relevant, I email the link to the article to them. I know that they now hate my emails, and I'm almost sure that they don't read most of them :D Anyway, it helps me get to know what is happening outside of my research interests. In addition to the abstracts, I also check the list of authors. I know that some of the authors publish on the same topics that I'm working on most of the time. If a paper passes through these papers, then it gets added to an special "list" on a Trello board that I call "Reading List". Papers stay on the "To Skim" list until I get back to them and then move them to the lists I have created for each project or topic. You can say that this reading list is quite big by now. Given that I have created this Trello board just months ago, I have started to feel that a Trello board might not have been the best choice for managing these number of items. However, so far I haven't found a replacement. In Trello, a card is created for each paper and it contains a link to the paper, sometimes a link to an implementation of the paper, and also a short summary or note I write about the paper from time to time. I also add labels to each card, which indicate whether I have already read the paper, is it work-related or not, what general topic does it belong to, and some other labels. However, you can't link cards to each other. As a result, you can't have a good ordering between a subset of papers. The problem is that to have proper ordering between papers, you need to have a graph, a simple list won't make it. That's why I still have problem ordering papers according to some features, around a central topic or research question.
To manage the actual articles, which I finally get to read, I use Mendeley. It is indeed a great service, it has a very good cross platform application and its document reader is quite functional. I am one of those who highlights papers heavily and in fact I have devised a color code for my highlights.

But in addition to reading the papers and highlighting them, I need somewhere to write other notes and sometimes try to work out the equations for myself once more. For that I use OneNote, one page for each paper.
The combination of Mendeley and OneNote works fine for the time being, although my cloud storage provided by Mendeley is filling up quickly.
Since I'm just a beginner, most of my time is spent reading other researchers' published work, but even now I feel that this process is not quite working. The discovery part is fine I think. I check out everything on arXiv. I also follow a large number of researchers and PhD students on Twitter and this stream is quite useful in staying on top of the best and latest research. The reading and taking note part is also a working combination. However, the managing and scheduling side of things is not close to being called "working". I still think that I need to find a better tool or combination of tools for managing the comparably large volume of research papers and schedule reading them. But all these stuff aside, it is really becoming very hard keeping up with the latest research. Checking out weekly papers on arXiv is a very time-consuming activity by itself, now imagine the list of accepted papers to a conference getting published! A true paper overflow.
How have you set up your research consumption workflow? How do you manage and schedule the ever-growing list of papers?
-
پژوهش و همکاری با sourced
به نام خدا
بعد از اینکه فرمان اجرایی ممنوعیت مهاجرت تبعهی هفت کشور توسط ترامپ امضا شد، صحبتی با آقای Eiso Kant پیش اومد در مورد وضعیت پژوهش در ایران و مشکلاتش. آقای Eiso Kant مدیرعامل و یکی از بنیانگذاران شرکت source{d} هستن. هدف این شرکت ساخت یک هوش مصنوعی هست که بتونه کد رو بفهمه. هدف بسیار جالبی هست و فکر میکنم خیلی کاربرد داشته باشه، حداقل برای کسایی که بلدن کد بزنن. البته هدف فراتر از این هم هست. برای اینکه بتونن به این هدف برسن لازمه که بتونن کد رو به خوبی بفهمن. به همین خاطر همهی کدهای موجود در گیتهاب و بیتباکت رو گرفتن و تحلیل کردن، پس اگر کدی روی هر کدوم از این سایتها داشتید که به صورت عمومی منتشر شده بود، جزو دادههایی که این شرکت جمع کرده و روشون تحلیل انجام داده قرار داشته. این شرکت کلی پروژهی جالب رو به صورت متنباز منتشر کرده که یه پیادهسازی از git به زبان Go و یک پیادهسازی الگوریتم خوشهبندی K-means بر روی کارت گرافیکی جزو جالبترین این پروژهها از نظر من هستن.
خلاصه بعد از اینکه صحبت در مورد پژوهش شد ایشون پیشنهاد دادن که علاقهمند هستن با کسایی که در حال حاضر در ایران مشغول پژوهش هستن یا میخوان پژوهش جدی داشته باشن، در زمینههایی که مرتبط به هدف شرکت باشه همکاری بکنن. برای اینکه توضیحی در مورد شرکت و هدفشون داده باشن و جزئیات و شرایط این همکاری مشخص باشه، یه ارائه آماده کردن که تو این لینک میتونید ببینیدش.
من فکر میکنم که همچنین همکاریهایی میتونه خیلی مناسب باشه و یک تجربهی آموزشی خیلی خوبی رو فراهم بکنه. پس اگر فکر میکنید که پیشنیازهای لازم رو دارید و در مورد پژوهش در این موضوعات جدی هستید (یا اگر حتی هنوز موضوع پایاننامهی ارشدتون رو تعریف نکردید)، توصیه میکنم حتماً باهاشون تماس بگیرید. اگر سوال دیگهای داشتید میتونید با من هم تماس بگیرید.
-
Paper notes for "A Context-aware Attention Network for Interactive Question Answering"
به نام خدا
I just read this paper that is submitted to ICRL 2017 and thought that I might write my notes as a post in the blog. It is a quite interesting and useful habit to publish these notes, but I have been a little lazy before. I'll try to publish more from now on.
A Context-aware Attention Network for Interactive Question Answering
Huayu Li, Martin Renqiang Min, Yong Ge, Asim Kadav
Link(s): OpenReview
Summary
It is an extension of the encoder-decoder framework for the task of question answering, which has two levels of attention when encoding sentences of the story and also when encoding the words of each sentence. Although "attention" term is used throughout the paper, "importance weighting" would better convey the idea of the paper. In addition to this, the other novelty of the paper is introducing a feedback mechanism for when the model doesn't have enough information to generate a correct answer. To test their model's ability to ask question from a user and obtain feedback, they also introduce a new dataset based on bAbI, named "ibAbI".
More in depth
This architecture consists of three main modules:
- Question Module
- Story Module
- Answer Module
Let's start by first looking at this figure from the paper.
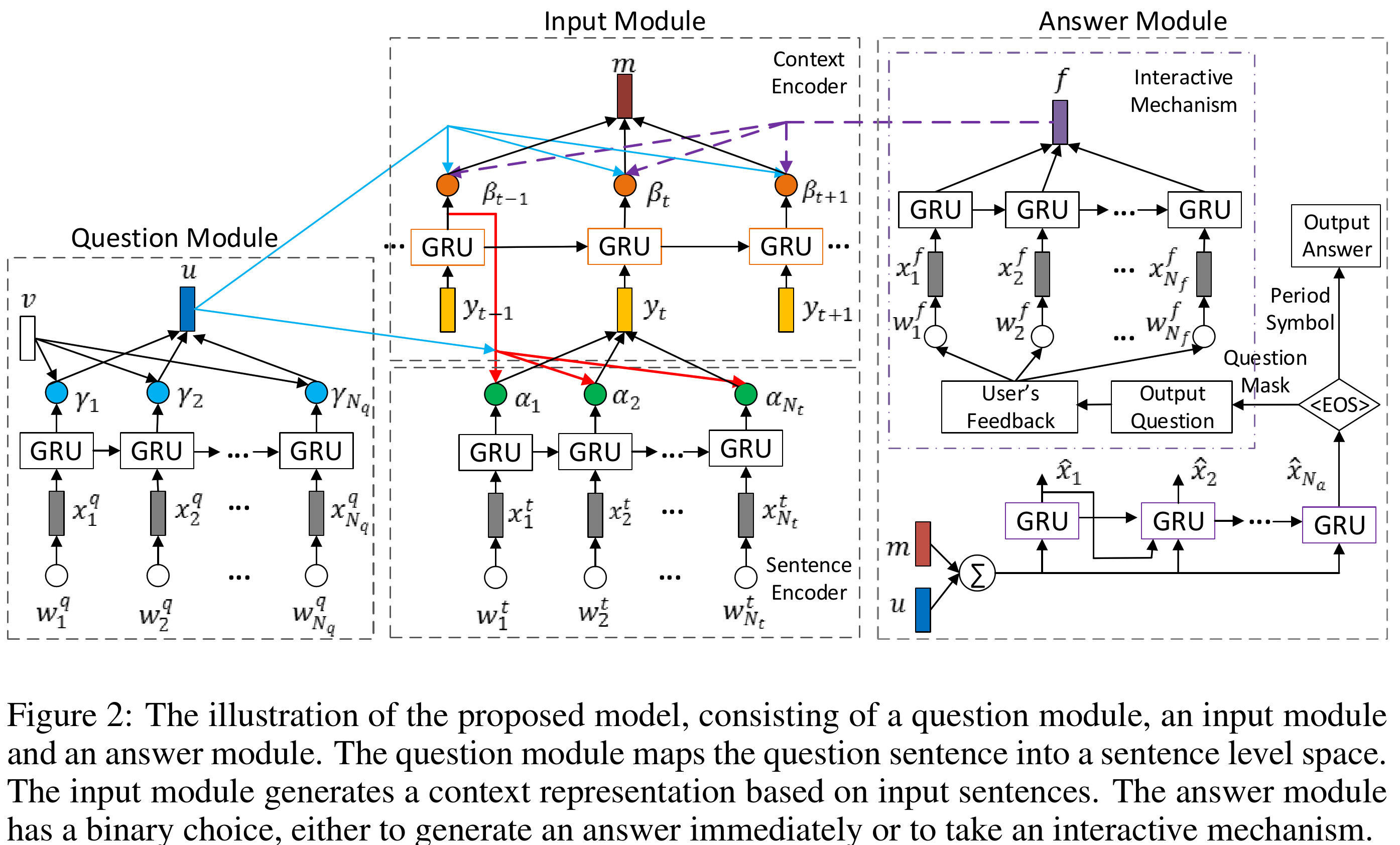
In the problem of textual question answering, we are given a question sentence and a sequence of story sentences. The goal is to find the answer to the question given the story sentences. Each sentence is a sequence of words.
Question Module
Given a question sentence as a sequence of words, $(\omega^q _ 1,\cdots,\omega _ {N _ q}^q)$, each word is first embedded using an embedding matrix \(\boldsymbol{W} _ \omega\). To achieve an encoding which takes the sequential nature of this sentence into account, a \(GRU _ \omega\) is used. Usually the last hidden state of the recurrent model is used as the encoding of a sequence. However, in this work, they use importance weighting (or "attention") to obtain the encoding of the sequence, using hidden states of the GRU throughout the sequence. To determine the importance of the hidden state at each time step, its similarity with a vector \(\mathbf{v}\) is used. This vector is learned jointly with the model. Although in general it doesn't look like a good idea to use a static vector to assess the importance of each word in a question sentence, however in this case, given mostly short questions, it seems to work. A better approach would be to use techniques like coattention, i.e. to use representation from the input sentences to assess the importance of words in the question sentence. In addition, it would be much better if results without this static attention were also reported, to show how much, if any, is this approach beneficial to the overall system. Anyways, after normalizing the "attention" weights using softmax, weighted some of hidden states is calculated and using a one-layer linear MLP, is projected into "context-level" vector space, thus
$$ \mathbf{u} = \mathbf{W} _ {ch} \sum _ {j=1}^{N _ q} \gamma _ j \mathbf{g} _ j ^ q + b _ c ^ {(q)} $$
So we have vector $\mathbf{u}$ as the vector representation of the question sentence.
Input Module
Sentence Encoder
"Input module aims at generating a representation for input sentences, including a sentence encoder and a context encoder". Input module is given a number of sentences each containing $N _ t$ words. Sentence encoder will encode each sentence into a vector representation, and then the context encoder will encode the sequence of sentence embeddings into a sequence of contextual embeddings, embeddings that take context into account. Let's start from the sentence encoder. As usual each word is embedded first using the embedding matrix $\boldsymbol{W} _ \omega$ (embedding matrices are shared in all modules). Then using a GRU, $GRU _ \omega$, these embeddings are transformed into a sequence of hidden states, $(\mathbf{h} ^ t _ 1, \cdots, \mathbf{h} ^ t _ {N _ t}).$ After this, the important step of word-level attention occurs. What is important and one of the main novelties of this work, is that contextual information from previous sentences is used in this step.
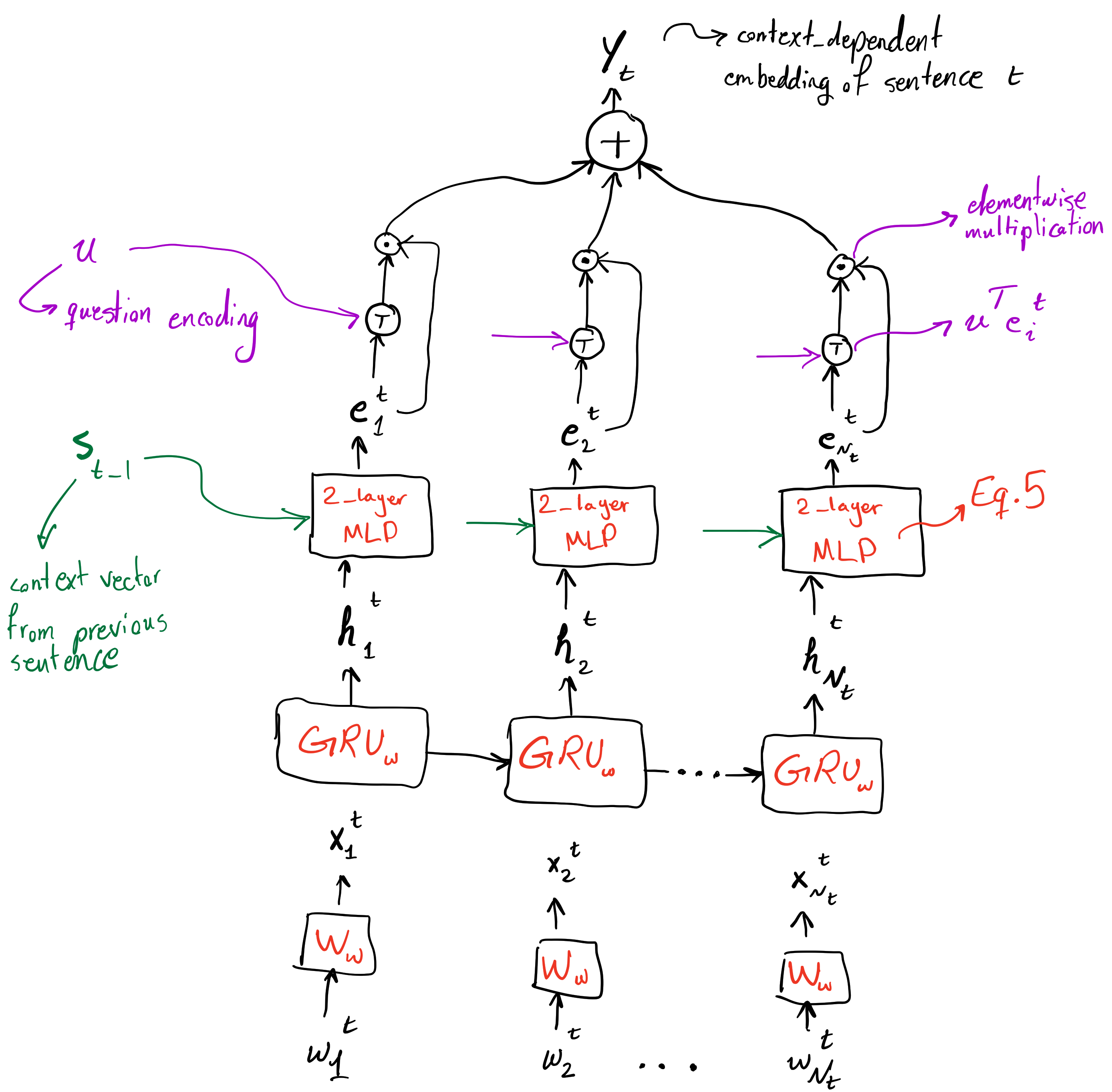
The diagram above is the missing figure from the paper! Well, just kidding. Figure 2 from paper is quite informative. This is just a supplementary diagram to make things more clear.
As can be seen in the figure above, after using a GRU's hidden states as preliminary representation of the input sentence words, a context vector from the last input sentence is used to transform hidden state representations to another representation which takes the overall context of previous sentences into account. For this transformation, a two layer MLP is used (Equation 5) to obtain the sequence of "context-injected" representations of sentence $l _ t$, $(\mathbf{e} ^ t _ 1, \cdots, \mathbf{e} ^ t _ {N _ t})$. Afterwards, vector representation of the question, $\mathbf{u}$, is used to obtain importance weighting of the words in the sentence and these weights, after being normalized, are used to get a weighted sum of the representations of words of sentence, $\mathbf{y} _ t$. This vector representation of sentence $l _ t$ not only has word-level attention, but also context from previous sentences have been taken into account.
A question that comes to mind is why this attention mechanism isn't incorporated inside the GRU itself? Although the current architecture has allowed the model to have shared parameters in GRUs when encoding the question, input sentences, and the feedback sentence, but it would be interesting to see how the model would perform if attention was baked into the GRU, like the Attentional GRU in the DMN+[1] paper.
Context Encoder
Context encoder simply uses another GRU, $GRU _ s$, to encode sequence of sentence representations from the sentence encoder into another sequence $(\mathbf{s} _ 1, \cdots, \mathbf{s} _ N)$. This lets the model encode the sequential structure into the representation obtained from the sentence encoder. Afterwards, just like the sentence encoder, inner product with question representation $\mathbf{u}$ is used to weight importance of each representation in the sequence of sentences. These weights are then used to get the input encoding vector $\mathbf{m}$ (Equations 8 and 9).
Answer Module
As clearly can be seen, this architecture is an extension of attention-less sequence to sequence models. It has the bottleneck vector representation $\mathbf{u} + \mathbf{m}$, which is used to condition the language model in the Answer Module. It doesn't have attention mechanism in the decoder, it only has the attention in the encoder portion of the architecture (similar to many VQA models). Although results are impressive (on the bAbI dataset), it would be interesting to see how this architecture (without the feedback mechanism) would fare against models that incorporate attention in their decoder.
The answer generation module is a language model that conditioned on the $\mathbf{u} + \mathbf{m}$ generates the answer to the question. However, the interesting part happens after this language model generates the first answer. There two EOS sentinel characters defined in this model, the question mark and the period. In case the generated sequence ends with a period, the model has decided that it has enough information to generate the answer to the question, given the input sentences. However, if the generated sequence ends with a question mark, it means that the model is asking for more feedback to be able to answer the question. After the model generates a question and gets a feedback, uses the representation of the feedback sentence, $\mathbf{f}$, to update its attention over the sequence of sentence embeddings. It is interesting that they use simple uniform importance weighting over the words of the feedback sentence to obtain its vector representation, instead of attention using the question representation, or the supplementary question generated by the model, or even only using the final state of the $GRU _ \omega$ used for processing the feedback sentence. The updated representation which is the sum of the question representation and the updated overall sentences representation is used to generate the final answer, given the feedback to the model. To simplify the model, they "allow the decoder to only generate at most one supplementary question". Although it may be tempting to allow the model to be able to ask more than one supplementary question, however since answer to these supplementary questions only would update the representation of the model of the input sentences, not increase model's overall knowledge, therefore it won't hurt much to limit the model to at most one supplementary question. The ability to increase model's knowledge using the feedback might make model more capable, although with increased complexity.
Experiments
They report that "training can be treated as a supervised classification problem" and they try "to minimize the cross-entropy error of the answer sequence and the supplementary question sequence". The evaluate their model on the bAbI dataset and a newly proposed ibAbI (interactive bAbI) dataset. They compare their models with DMN+[1], MemN2N[2], and a simple EncDec[3] model. Their model successfully manages to solve 19 out of 20 of the bAbI tasks (Table 4). They also get significantly better results on the ibAbI dataset compared to the other models evaluated.
Final words
The paper was interesting, although short of some details. They could also compare their models against an additional number of other models. It would also be great if they could provide an open source implementation of the proposed model. I still can't think of a way to implement the Input Module. If you have any suggestions comment below.
[1] Caiming Xiong, Stephen Merity, and Richard Socher. Dynamic memory networks for visual and textual question answering. In ICML, pp. 2397–2406, 2016.
[2] Sukhbaatar Sainbayar, Szlam Arthur,Weston Jason, and Fergus Rob. End-to-end memory networks. In NIPS, pp. 2440–2448, 2015.
[3] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In EMNLP, pp. 1724–1734, 2014.
-
آفیس رایگان برای دانشجویان
به نام خدا
چون دانشجویان در سراسر دنیا قشر فقیری هست(!)، بخاطر همین خیلی از شرکتهای نرمافزاری سعی میکنن بعضی از سرویسها و نرمافزارهاشون رو با قیمت پایین یا به صورت رایگان به دانشجویان ارائه بکنن. نمونهاش مثلاً گیتهابه که پنج تا repository خصوصی به هر دانشجو میده، یا مثلاً شرکت Autodesk نرمافزار AutoCAD یا یه تعداد دیگهای از نرمافزارهاش رو به صورت رایگان میده، شرکت Jetbrains اجازهی استفاده از IDEهاش و البته Resharper رو به صورت رایگان میده و کلی چیز دیگه که اگر بگردید حتماً پیدا میکنید.
یکی دیگه از شرکتهایی که از قدیم کلی خدمات رایگان به دانشجوها میده شرکت Microsoft هست. این شرکت تحت برنامهی Dreamspark یه سری از خدمات رو از سالها قبل ارائه میداد، خدماتی مثل Windows Server، SQL Server، Microsoft R Server و البته خدماتی با همکاری شرکتهای دیگه مثل Github و Xamarin و یه مدت استفاده از آموزشهای سایت Pluralsight. قدیمها هم که ویژوال استودیو کلاً نسخهی رایگان نداشت، نسخهی Professional ویژوال استودیو رو هم میشد از طریق این برنامه گرفت. ولی الان که نسخهی رایگان Community به نسخههای ویژوال استودیو اضافه شده نیاز به این خدمت کم شده. راستی اخیراً هم اکانت رایگان Azure به کاتالوگ خدمات Dreamspark اضافه شده که البته فعلاً نمیشه از ایران فعالش کرد. باید صبر کرد ببینیم این مشکل رو حل میکنن یا نه.
قبلاً از طریق برنامهی Dreamspark میشد تخفیف برای خرید subscription آفیس 365 گرفت، ولی این رو برداشتن.
به جاش الان آفیس 365 به صورت رایگان به دانشجوها داده میشه!! :)
شاید یک سال قبل (یا کمتر یا بیشتر، دقیق یادم نیست) بود که اعلام شد مایکروسافت به دانشجوها subscription آفیس 365 رو به صورت رایگان ارائه خواهد داد. برای اینکار هم نیاز به این دارید که آدرس ایمیل از طرف دانشگاه با دامنهی .edu داشته باشید.
مشکل این بود که این امکان برای ایران نبود، یعنی با ایمیل دانشگاههای ایرانی نمیشد این کار رو کرد. ولی امروز به صورت اتفاقی دوباره سعی کردم این کار رو بکنم و موفق شدم. یعنی احتمالاً مدتی هست که این امکان فراهم شده و بالاخره از اینجا با ایمیل دانشگاههای ایرانی هم میشه آفیس 365 رو گرفت. برای اینکار کافیه به این آدرس برید و با وارد کردن ایمیل دانشگاهیتون حساب آفیس 365 رو دریافت کنید. با این کار یک ترابایت فضای رایگان روی OneDrive میگیرید. بعد میتونید نرمافزار آفیس رو بدون نیاز به کرک کردن استفاده کنید (البته من رو نسخهی Office Standard امتحان کردم، چون این برنامه شامل نرمافزارهای Word، PowerPoint، OneNote و Excel میشه) نسخههای دیگه شامل نرمافزارهای دیگهای هستن که توی این توافقنامه نیستن. در ضمن با این کار میشه آفیس رو روی 5 تا از کامپیوترهاتون استفاده کنید (PC و Mac) (توجه کنید روی کامپیوترهاتون، نه روی کامپیوتر خودتون و کسای دیگه، این License فقط به یک شخص حقیقی داده میشه). بعد روی موبایل و تبلتتون هم میتونید ازش استفاده کنید (روی همهی سیستمعاملها).
سلب مسئولیت (فارسی همون Disclaimer): من این کارها رو با ایمیل دانشگاهی که توش مشغول تحصیل هستم (دانشگاه شریف) امتحان کردم، در مورد دانشگاههای دیگهی ایران اطلاعی ندارم.
-
آدرس جدید!
به نام خدا
راستی آدرس اینجا هم تغییر کرده. یعنی علاوه بر اینکه میشه با آدرس قبلی http://erfannoury.github.io به اینجا دسترسی پیدا کرد، حالا آدرس http://blog.erfan.xyz هم اضافه شده. با این آدرس هم میشه به بلاگ دسترسی پیدا کرد.
-
نصب کتابخانهی Theano در ویندوز (بهروزرسانی)
به نام خدا
بعد از پست قبلی در مورد نصب Theano بر روی ویندوز، تغییرات زیادی در این زمینه و کتابخانههای یادگیری عمیق و وضعیت نصب اونها روی ویندوز ایجاد شده. این پست به نوعی بهروزرسانی بر روی موضوع نصب این کتابخانهی پایهای و بعد معرفی یک کتابخانهی جدیده.
نکات جدید برای نصب Theano
چند روز پیش میخواستم این کتابخانه رو روی یک کامپیوتر جدید نصب کنم. اولین کاری که کردم دانلود کردن و نصب Anaconda Python، CUDA 7.0 و البته Visual Studio 2013 بود. بخاطر اینکه هنوز CUDA از Visual Studio 2015 پشتیبانی نمیکنه، سراغ نسخهی جدیدش نرفتم. بعد از اینکه اینا رو نصب کردم (اول ویژوال استودیو، بعد پایتون، در نهایت کودا) رفتم سراغ نصب gcc. درسته که برای کامپایلکردن قسمت اصلی کد Theano از کامپایلر مایکروسافت استفاده میشه، ولی بعضی از تیکههای کد نیاز به gcc دارن. برای اینکار TDM GCC رو دانلود و نصب کردم. این نسخه از بقیه زودتر آپدیت میشه و چیز اضافیای هم نصب نمیکنه. بعد از اینکه همهی اینها رو نصب کردم و مطمئن شدم که همهی چیزهای لازم در مسیر سیستم قرار گرفتن رفتم سراغ نصب Theano.
اولین مشکلی که خوردم این بود که وقتی از gcc میخواست استفاده کنه خطای عدم وجود فایلهای لازم برای پایتون رو میداد. رفتم خوب مسیر پایتون (پوشهی libs) رو بررسی کردم. دیدم که همه چیز درسته. بعد از کمی جستجو، فهمیدم که gcc نیاز به فایلهای کتابخانهای با فرمت
libpython27.aداره، نهpython27.lib. بنابراین باید اول این فایل رو پیدا (یا درست) میکردم و بعد در همون پوشه قرار میدادم. بعد از اینکار یکی از مشکلات کامپایل حل شد. برای حل مشکل به این لینک یه نگاهی بندازید.مشکل دیگه یه مشکل خیلی عجیب بود. اینکه
C:\Windows\System32تو مسیرهای سیستمی نبود. خیلی عجیب بود این موضوع برام و باعث ایجاد کلی مشکل و گرفتن کلی وقت شد. ولی بعد از اضافه کردن مسیر، کتابخانه به صورت کامل کامپایل شد.بعد از این، نوبت درست کردن فایل تنظیمات کتابخانه، یعنی
.theanorcبود. این رو هم در مسیر کاربری قرار دادم و بعدش رفتم سراغ اجرای کتابخانه که بدون مشکل اجرا شد. اینجا به عنوان مرجع، محتوای فایل تنظیمات Theano رو میذارم.[blas] ldflags = [nvcc] flags=-LC:\Anaconda\libs compiler_bindir=C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin optimizer_including=dnn fastmath = True [global] device = gpu floatX = float32 [cuda] root=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.0البته اگر خوب ببینید قسمت blas خالیه. برای اون قسمت هم کتابخانهی OpenBLAS رو دانلود کردم و مسیر اون کتابخانه و همچنین اسم فایل کتابخانهی OpenBLAS رو به عنوان ورودی دادم.
بعد از این مراحل فکر نمیکنم مشکلی در نصب Theano پیش بیاد.
اون dnn هم که نوشتم همون cuDNN هست که انویدیا عرضه کرده تا محاسبات مرتبط با یادگیری عمیق سریعتر بشه. نصب اون هم راحته. بعد از اینکه فایلهاش رو دانلود کردید، تو پوشههای مرتبط توی محل نصب CUDA قرارشون بدید و اینجا هم اون خط رو به فایل تنظیمات اضافه کنید. cuDNN 2 روی ویندوز بدون مشکل کار میکنه، ولی cuDNN 3 رو هنوز امتحان نکردم.
کتابخانهی Keras
کتابخانهی یادگیری عمیق Keras یکی از اون کتابخانههای یادگیری عمیقه که به نظر میاد آیندهی بسیار درخشانی داشته باشه. این کتابخانه روی Theano ساخته شده، ولی API اون از Torch7 الهام گرفته شده و خیلی خوشدسته. برخلاف پیچیدگیهای بالای کار با Theano، کد مربوط به این کتابخانه خیلی خوانا است و به راحتی میتونید توش به طراحی مدل و آموزش و تحلیل مدل بپردازید. واقعاً بین همهی کتابخانههای یادگیری عمیقی که بررسی کردم (برای پایتون البته)، این بهترین گزینه برای شروع کاره. آموزشها و راهنماییهای بسیار خوبی هم تو این آدرس گذاشتن. حتماً اگر تصمیم دارید کار روی یادگیری عمیق رو بدون مشکلات زیاد شروع کنید نگاهی به این کتابخانه بندازید.
در کل بخاطر اینکه افراد و شرکتهای زیادی پشت کتابخانههای Caffe و Torch7 بودن بقیهی کتابخانهها تقریباً عقب مونده بودن. ولی اخیراً احساس میکنم که کتابخانههای مبتنی بر Theano دارن جایگاه خودشون رو قویتر میکنن. خیلی از مقالات اخیر با این کتابخانههای پیادهسازی شدن و همچنین پیادهسازی مقالات زیادی توسط افراد ثالث برای این کتابخانهها انجام میگیره.
هر چقدر گزینهها برای کار کردن زیاد باشن، بهتره. امیدوارم که روز به روز کتابخانهها پیشرفتهتر و البته ورود به اونها سادهتر بشه.
فکر میکنم در روزهای آتی پستهای متعددی داشته باشم.