به نام خدا
I just read this paper that is submitted to ICRL 2017 and thought that I might write my notes as a post in the blog. It is a quite interesting and useful habit to publish these notes, but I have been a little lazy before. I'll try to publish more from now on.
A Context-aware Attention Network for Interactive Question Answering
Huayu Li, Martin Renqiang Min, Yong Ge, Asim Kadav
Link(s): OpenReview
Summary
It is an extension of the encoder-decoder framework for the task of question answering, which has two levels of attention when encoding sentences of the story and also when encoding the words of each sentence. Although "attention" term is used throughout the paper, "importance weighting" would better convey the idea of the paper. In addition to this, the other novelty of the paper is introducing a feedback mechanism for when the model doesn't have enough information to generate a correct answer. To test their model's ability to ask question from a user and obtain feedback, they also introduce a new dataset based on bAbI, named "ibAbI".
More in depth
This architecture consists of three main modules:
- Question Module
- Story Module
- Answer Module
Let's start by first looking at this figure from the paper.
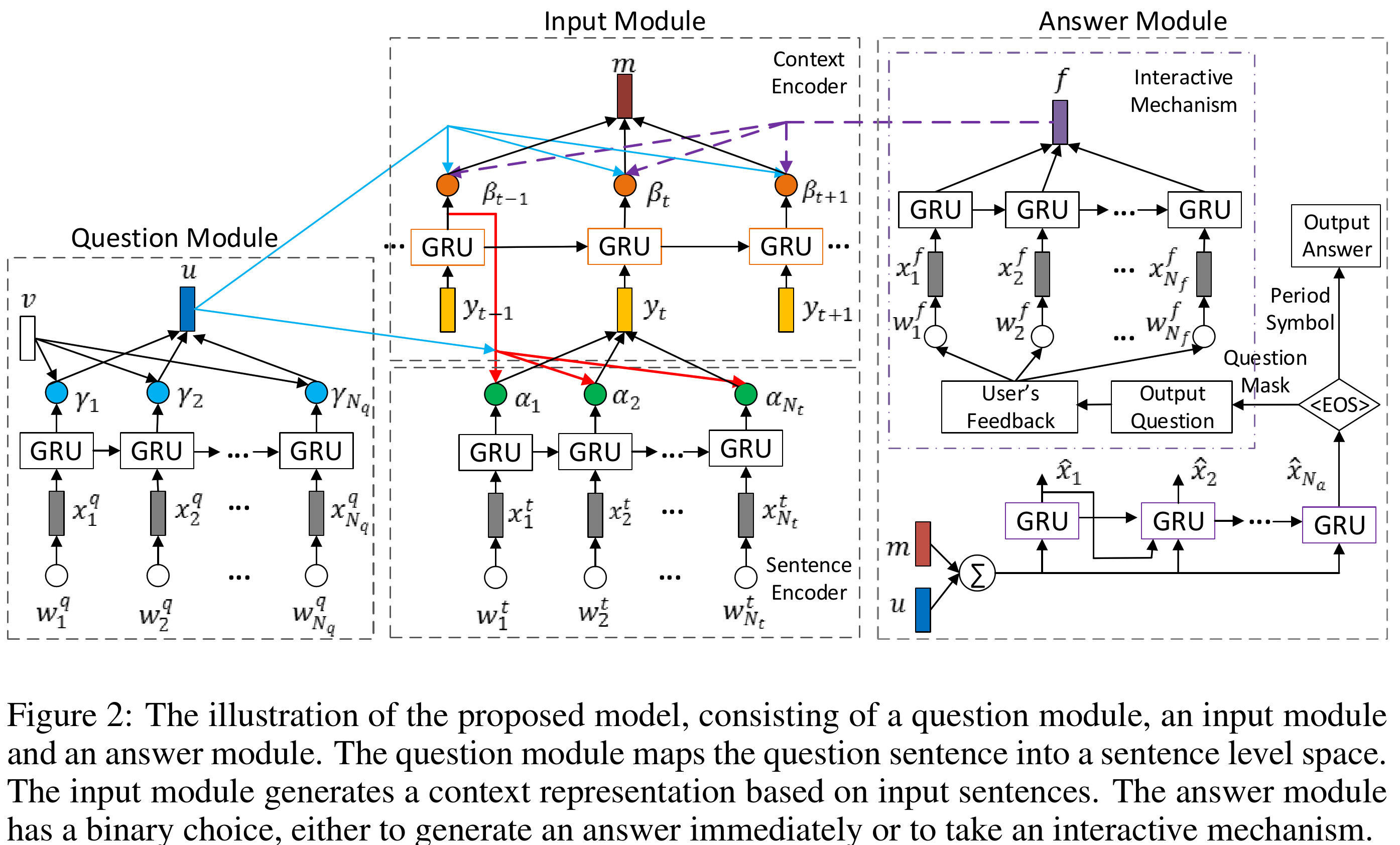
In the problem of textual question answering, we are given a question sentence and a sequence of story sentences. The goal is to find the answer to the question given the story sentences. Each sentence is a sequence of words.
Question Module
Given a question sentence as a sequence of words, $(\omega^q _ 1,\cdots,\omega _ {N _ q}^q)$, each word is first embedded using an embedding matrix \(\boldsymbol{W} _ \omega\). To achieve an encoding which takes the sequential nature of this sentence into account, a \(GRU _ \omega\) is used. Usually the last hidden state of the recurrent model is used as the encoding of a sequence. However, in this work, they use importance weighting (or "attention") to obtain the encoding of the sequence, using hidden states of the GRU throughout the sequence. To determine the importance of the hidden state at each time step, its similarity with a vector \(\mathbf{v}\) is used. This vector is learned jointly with the model. Although in general it doesn't look like a good idea to use a static vector to assess the importance of each word in a question sentence, however in this case, given mostly short questions, it seems to work. A better approach would be to use techniques like coattention, i.e. to use representation from the input sentences to assess the importance of words in the question sentence. In addition, it would be much better if results without this static attention were also reported, to show how much, if any, is this approach beneficial to the overall system. Anyways, after normalizing the "attention" weights using softmax, weighted some of hidden states is calculated and using a one-layer linear MLP, is projected into "context-level" vector space, thus
$$ \mathbf{u} = \mathbf{W} _ {ch} \sum _ {j=1}^{N _ q} \gamma _ j \mathbf{g} _ j ^ q + b _ c ^ {(q)} $$
So we have vector $\mathbf{u}$ as the vector representation of the question sentence.
Input Module
Sentence Encoder
"Input module aims at generating a representation for input sentences, including a sentence encoder and a context encoder". Input module is given a number of sentences each containing $N _ t$ words. Sentence encoder will encode each sentence into a vector representation, and then the context encoder will encode the sequence of sentence embeddings into a sequence of contextual embeddings, embeddings that take context into account. Let's start from the sentence encoder. As usual each word is embedded first using the embedding matrix $\boldsymbol{W} _ \omega$ (embedding matrices are shared in all modules). Then using a GRU, $GRU _ \omega$, these embeddings are transformed into a sequence of hidden states, $(\mathbf{h} ^ t _ 1, \cdots, \mathbf{h} ^ t _ {N _ t}).$ After this, the important step of word-level attention occurs. What is important and one of the main novelties of this work, is that contextual information from previous sentences is used in this step.
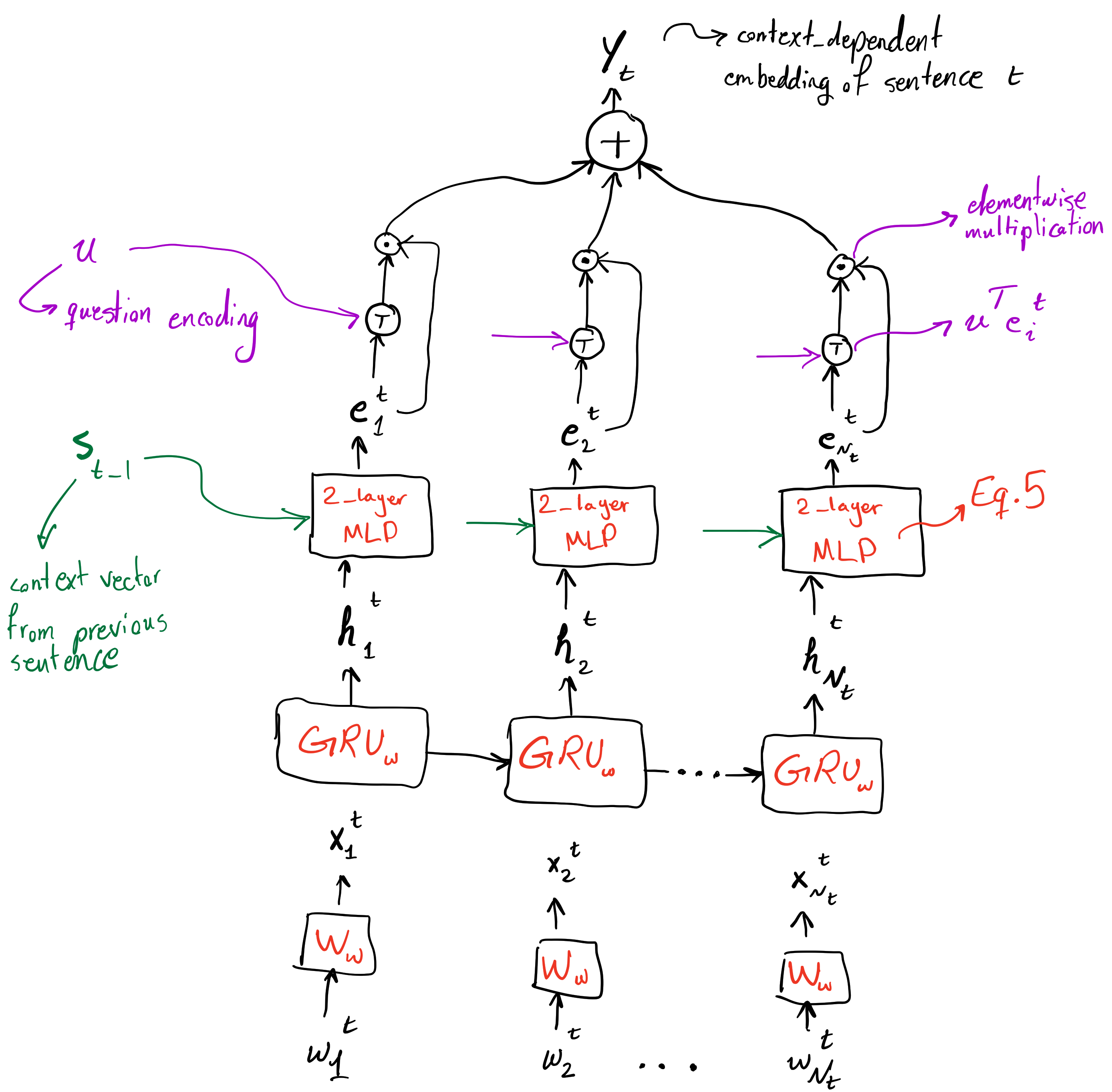
The diagram above is the missing figure from the paper! Well, just kidding. Figure 2 from paper is quite informative. This is just a supplementary diagram to make things more clear.
As can be seen in the figure above, after using a GRU's hidden states as preliminary representation of the input sentence words, a context vector from the last input sentence is used to transform hidden state representations to another representation which takes the overall context of previous sentences into account. For this transformation, a two layer MLP is used (Equation 5) to obtain the sequence of "context-injected" representations of sentence $l _ t$, $(\mathbf{e} ^ t _ 1, \cdots, \mathbf{e} ^ t _ {N _ t})$. Afterwards, vector representation of the question, $\mathbf{u}$, is used to obtain importance weighting of the words in the sentence and these weights, after being normalized, are used to get a weighted sum of the representations of words of sentence, $\mathbf{y} _ t$. This vector representation of sentence $l _ t$ not only has word-level attention, but also context from previous sentences have been taken into account.
A question that comes to mind is why this attention mechanism isn't incorporated inside the GRU itself? Although the current architecture has allowed the model to have shared parameters in GRUs when encoding the question, input sentences, and the feedback sentence, but it would be interesting to see how the model would perform if attention was baked into the GRU, like the Attentional GRU in the DMN+[1] paper.
Context Encoder
Context encoder simply uses another GRU, $GRU _ s$, to encode sequence of sentence representations from the sentence encoder into another sequence $(\mathbf{s} _ 1, \cdots, \mathbf{s} _ N)$. This lets the model encode the sequential structure into the representation obtained from the sentence encoder. Afterwards, just like the sentence encoder, inner product with question representation $\mathbf{u}$ is used to weight importance of each representation in the sequence of sentences. These weights are then used to get the input encoding vector $\mathbf{m}$ (Equations 8 and 9).
Answer Module
As clearly can be seen, this architecture is an extension of attention-less sequence to sequence models. It has the bottleneck vector representation $\mathbf{u} + \mathbf{m}$, which is used to condition the language model in the Answer Module. It doesn't have attention mechanism in the decoder, it only has the attention in the encoder portion of the architecture (similar to many VQA models). Although results are impressive (on the bAbI dataset), it would be interesting to see how this architecture (without the feedback mechanism) would fare against models that incorporate attention in their decoder.
The answer generation module is a language model that conditioned on the $\mathbf{u} + \mathbf{m}$ generates the answer to the question. However, the interesting part happens after this language model generates the first answer. There two EOS sentinel characters defined in this model, the question mark and the period. In case the generated sequence ends with a period, the model has decided that it has enough information to generate the answer to the question, given the input sentences. However, if the generated sequence ends with a question mark, it means that the model is asking for more feedback to be able to answer the question. After the model generates a question and gets a feedback, uses the representation of the feedback sentence, $\mathbf{f}$, to update its attention over the sequence of sentence embeddings. It is interesting that they use simple uniform importance weighting over the words of the feedback sentence to obtain its vector representation, instead of attention using the question representation, or the supplementary question generated by the model, or even only using the final state of the $GRU _ \omega$ used for processing the feedback sentence. The updated representation which is the sum of the question representation and the updated overall sentences representation is used to generate the final answer, given the feedback to the model. To simplify the model, they "allow the decoder to only generate at most one supplementary question". Although it may be tempting to allow the model to be able to ask more than one supplementary question, however since answer to these supplementary questions only would update the representation of the model of the input sentences, not increase model's overall knowledge, therefore it won't hurt much to limit the model to at most one supplementary question. The ability to increase model's knowledge using the feedback might make model more capable, although with increased complexity.
Experiments
They report that "training can be treated as a supervised classification problem" and they try "to minimize the cross-entropy error of the answer sequence and the supplementary question sequence". The evaluate their model on the bAbI dataset and a newly proposed ibAbI (interactive bAbI) dataset. They compare their models with DMN+[1], MemN2N[2], and a simple EncDec[3] model. Their model successfully manages to solve 19 out of 20 of the bAbI tasks (Table 4). They also get significantly better results on the ibAbI dataset compared to the other models evaluated.
Final words
The paper was interesting, although short of some details. They could also compare their models against an additional number of other models. It would also be great if they could provide an open source implementation of the proposed model. I still can't think of a way to implement the Input Module. If you have any suggestions comment below.
[1] Caiming Xiong, Stephen Merity, and Richard Socher. Dynamic memory networks for visual and textual question answering. In ICML, pp. 2397–2406, 2016.
[2] Sukhbaatar Sainbayar, Szlam Arthur,Weston Jason, and Fergus Rob. End-to-end memory networks. In NIPS, pp. 2440–2448, 2015.
[3] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In EMNLP, pp. 1724–1734, 2014.
comments powered by Disqus